Tracing
This guide walks through how to trace your code in Braintrust. Tracing is an invaluable tool for exploring the sub-components of your program which produce each top-level input and output. We currently support tracing in logging and evaluations.
Before proceeding, make sure to read the quickstart guide and setup an API key.

Traces: the building block of logs
The core building blocks of logging are spans and traces. A span represents a unit of work, with a start and end time, and optional fields like input, output, metadata, scores, and metrics (the same fields you can log in an Experiment). Each span contains one or more children, which are usually run within their parent span (e.g. a nested function call). Common examples of spans include LLM calls, vector searches, the steps of an agent chain, and model evaluations.
Together, spans form a trace, which represents a single independent request. Each trace is visible as a row in the final table. Well-designed traces make it easy to understand the flow of your application, and to debug issues when they arise. The rest of this guide walks through how to log rich, helpful traces. The tracing API works the same way whether you are logging online (production logging) or offline (evaluations), so the examples below apply to either use-case.
Annotating your code
To log a trace, you simply wrap the code you want to trace. Braintrust will automatically capture and log information behind the scenes.
Wrapping OpenAI
Braintrust includes a wrapper for the OpenAI API that automatically logs your
requests. To use it, simply call wrapOpenAI/wrap_openai on your OpenAI
instance. We intentionally do not monkey
patch the libraries directly, so
that you can use the wrapper in a granular way.

When using wrapOpenAI/wrap_openai, you technically do not need to use traced or start_span. In fact, just
initializing a logger is enough to start logging LLM calls. If you use traced or start_span, you will create more
detailed traces that include the functions surrounding the LLM calls and can group multiple LLM calls together.
Streaming metrics
wrap_openai/wrapOpenAI will automatically log metrics like prompt_tokens, completion_tokens, and total_tokens for
streaming LLM calls if the LLM API returns them. OpenAI only returns these metrics if you set include_usage to true in
the stream_options parameter.
Wrapping a custom LLM client
If you're using your own client, you can wrap it yourself using the same conventions as the OpenAI wrapper. Feel free to check out the Python and TypeScript implementations for reference.
To track the span as an LLM, you must:
- Specify the
typeasllm. You can specify anynameyou'd like. This enables LLM duration metrics. - Add
prompt_tokens,completion_tokens, andtotal_tokensto themetricsfield. This enables LLM token usage metrics. - Format the
inputas a list of messages (using the OpenAI format), and put other parameters (likemodel) inmetadata. This enables the "Try prompt" button in the UI.
Errors
When you run:
- Python code inside of the
@traceddecorator or within astart_span()context - TypeScript code inside of
traced(or awrappedTracedfunction)
Braintrust will automatically log any exceptions that occur within the span.

Under the hood, every span has an error field which you can also log to directly.
Deeply nested code
Often, you want to trace functions that are deep in the call stack, without
having to propagate the span object throughout. Braintrust uses async-friendly
context variables to make this workflow easy:
- The
tracedfunction/decorator will create a span underneath the currently-active span. - The
currentSpan()/current_span()method returns the currently active span, in case you need to do additional logging.
Multimodal content
Uploading attachments
In addition to text and structured data, Braintrust also supports uploading file attachments (blobs). This is especially useful when working with multimodal models, which can require logging large image, audio, or video files. You can also use attachments to log other unstructured data related to your LLM usage, such as a user-provided PDF file that your application later transforms into an LLM input.
To upload an attachment, create a new
Attachment object to
represent the file on disk or binary data in memory to be uploaded. You can
place the Attachment object anywhere in the event to be logged, including in
arrays/lists or deeply nested in objects.
Attachments are currently supported in the TypeScript SDK. Python support is coming soon.
The SDK uploads the attachments separately from other parts of the log, so the presence of attachments doesn't affect logging performance.
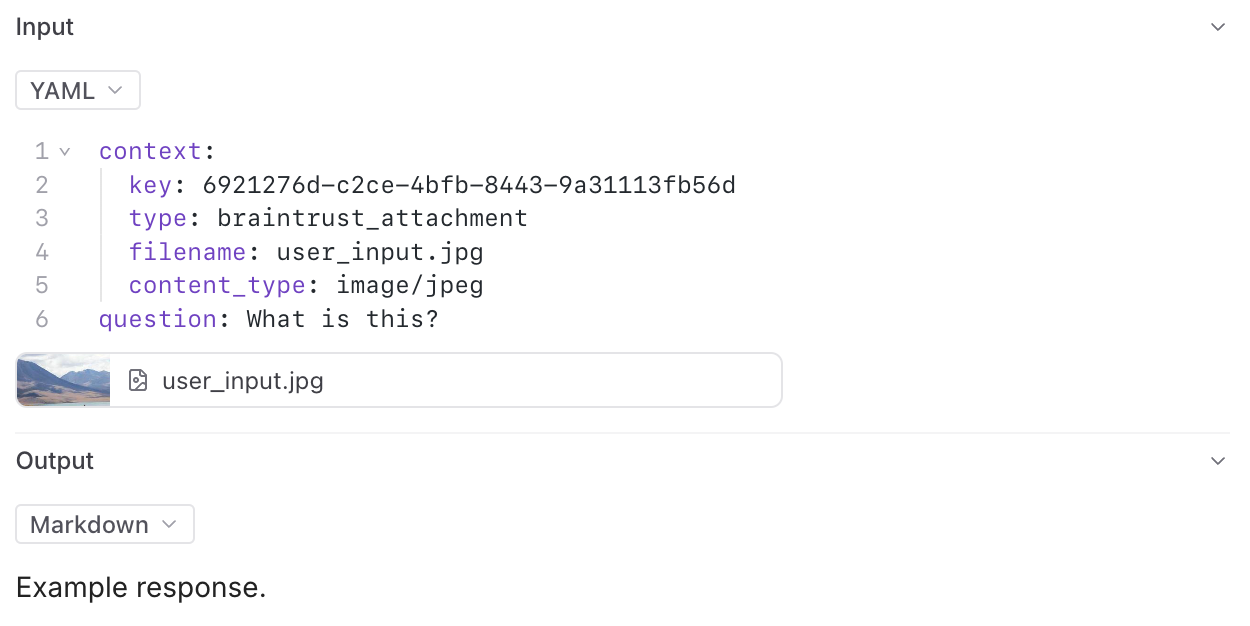
Image, audio, video, and PDF attachments can be previewed in Braintrust. All attachments can be downloaded for viewing locally.
Linking to external images
To log an external image, provide an image URL or base64 encoded image as a string. The tree viewer will automatically render the image.

The tree viewer will look at the URL or string to determine if it is an image. If you want to force the viewer to treat it as an image, then nest it in an object like
and the viewer will render it as an image. Base64 images must be rendered in URL format, just like the OpenAI API. For example:
Tracing integrations
Vercel AI SDK
The Vercel AI SDK is an elegant tool for building AI-powered applications. You can wrap the SDK in Braintrust to automatically log your requests.
Instructor
To use Instructor to generate structured outputs, you need to wrap the
OpenAI client with both Instructor and Braintrust. It's important that you call Braintrust's wrap_openai first,
because it uses low-level usage info and headers returned by the OpenAI call to log metrics to Braintrust.
Langchain
To trace Langchain code in Braintrust, you can use the BraintrustTracer callback handler. The callback
handler is currently only supported in Python, but if you need support for other languages, please
let us know.
To use it, simply initialize a BraintrustTracer and pass it as a callback handler to langchain objects
you create.
OpenTelemetry (OTel)
To set up Braintrust as an OpenTelemetry backend, you'll need to route the traces to Braintrust's OpenTelemetry endpoint, set your API key, and specify a parent project or experiment.
Braintrust supports a combination of common patterns from OpenLLMetry and popular libraries like the Vercel AI SDK. Behind the scenes, clients can point to Braintrust's API as an exporter, which makes it easy to integrate without having to install additional libraries or code. OpenLLMetry supports a range of languages including Python, TypeScript, Java, and Go, so it's an easy way to start logging to Braintrust from many different environments.
Once you set up an OpenTelemetry Protocol Exporter (OTLP) to send traces to Braintrust, we automatically
convert LLM calls into Braintrust LLM spans, which
can be saved as prompts
and evaluated in the playground.
For collectors that use the OpenTelemetry SDK to export traces, set the following environment variables:
The trace endpoint URL is https://api.braintrust.dev/otel/v1/traces. If your exporter
uses signal-specific environment variables, you'll need to set the full path:
OTEL_EXPORTER_OTLP_TRACES_ENDPOINT=https://api.braintrust.dev/otel/v1/traces
If you're self-hosting Braintrust, substitute your stack's Universal API URL. For example:
OTEL_EXPORTER_OTLP_ENDPOINT=https://dfwhllz61x709.cloudfront.net/otel
The x-bt-parent header sets the trace's parent project or experiment. You can use
a prefix like project_id:, project_name:, or experiment_id: here, or pass in
a span slug
(span.export()) to nest the trace under a span within the parent object.
Vercel AI SDK
To use the Vercel AI SDK to send
telemetry data to Braintrust, set these environment variables in your Next.js
app's .env file:
You can then use the experimental_telemetry option to enable telemetry on
supported AI SDK function calls:
Traced LLM calls will appear under the Braintrust project or experiment
provided in the x-bt-parent header.
Traceloop
To export OTel traces from Traceloop OpenLLMetry to Braintrust, set the following environment variables:
Traces will then appear under the Braintrust project or experiment provided in
the x-bt-parent header.
LlamaIndex
To trace LLM calls with LlamaIndex, you can use the OpenInference LlamaIndexInstrumentor to send OTel traces directly to Braintrust. Configure your environment and set the OTel endpoint:
Now traced LLM calls will appear under the provided Braintrust project or experiment.
Distributed tracing
Sometimes it's useful to be able to start a trace in one process and continue it
in a different one. For this purpose, Braintrust provides an export function
which returns an opaque string identifier. This identifier can be passed to
start_span to resume the trace elsewhere. Consider the following example of
tracing across separate client and server processes.
Client code
Server code
Updating spans
Similar to distributed tracing, it can be useful to update spans after you initially log them. For example, if you collect the output of a span asynchronously.
The Experiment and Logger classes each have an updateSpan() method, which you can call with
the span's id to perform an update:
You can also use span.export() to export the span in a fully contained string, which is useful if you
have multiple loggers or perform the update from a different service.
It's important to make sure the update happens after the original span has been logged, otherwise they can trample on each other.
Distributed tracing is designed specifically to prevent this edge case, and instead works by logging a new (sub) span.
Deep-linking to spans
The Span.permalink method formats a permalink to the Braintrust application
for viewing the span. The link will open the UI to the row represented by the
Span object.
If you do not have access to the original Span object, the slug produced by
Span.export contains enough information to produce the same permalink. The
braintrust.permalink function can be used to construct a deep link to the row
in the UI from a given span slug.
Manually managing spans
In more complicated environments, it may not always be possible to wrap the entire duration of a span within a single block of code. In such cases, you can always pass spans around manually.
Consider this hypothetical server handler, which logs to a span incrementally over several distinct callbacks:
Custom rendering for span fields
Although the built-in span viewers cover a variety of different span field display types— YAML, JSON, Markdown, LLM calls, and more—you may
want to further customize the display of your span data. For example, you could include the id of an internal database
and want to fetch and display its contents in the span viewer. Or, you may want to reformat the data in the span in a way
that's more useful for your use case than the built-in options.
To support these use cases, Braintrust supports custom span iframe viewers. To enable a span iframe, visit the Configuration tab of a project, and create one. You can define the URL, and then customize its behavior:
- Provide a title, which is displayed at the top of the section.
- Provide, via mustache, template parameters to the URL. These parameters are
in terms of the top-level span fields, e.g.
{{input}},{{output}},{{expected}}, etc. or their subfields, e.g.{{input.question}}. - Allow Braintrust to send a message to the iframe with the span data, which is useful when the data may be very large and not fit in a URL.
 In this example, the "Table" section is a custom span iframe.
In this example, the "Table" section is a custom span iframe.
Iframe message format
In Zod format, the message schema looks like this:
Example code
To help you get started, check out the braintrustdata/braintrust-viewers repository on Github, which contains example code for rendering a table, X/Tweet, and more.
Importing and exporting spans
Spans are processed in Braintrust as a simple format, consisting of input, output, expected, metadata, scores,
and metrics fields (all optional), as well as a few system-defined fields which you usually do not need to mess with, but
are described below for completeness. This simple format makes
it easy to import spans captured in other systems (e.g. languages other than TypeScript/Python), or to export spans from
Braintrust to consume in other systems.
Underlying format
The underlying span format contains a number of fields which are not exposed directly through the SDK, but are useful to understand when importing/exporting spans.
idis a unique identifier for the span, within the container (e.g. an experiment, or logs for a project). You can technically set this field yourself (to overwrite a span), but it is recommended to let Braintrust generate it automatically.input,output,expected,scores,metadata, andmetricsare optional fields which describe the span and are exposed in the Braintrust UI. When you use the TypeScript or Python SDK, these fields are validated for you (e.g. scores must be a mapping from strings to numbers between 0 and 1).span_attributescontains attributes about the span. Currently the recognized attributes arename, which is used to display the span name in the UI, andtype, which displays a helpful icon.typeshould be one of"llm","score","function","eval","task", or"tool".- Depending on the container, e.g. an experiment, or project logs, or a dataset, fields like
project_id,experiment_id,dataset_id, andlog_idare set automatically, by the SDK, so the span can be later retrieved by the UI and API. You should not set these fields yourself. span_id,root_span_id, andspan_parentsare used to construct the span tree and are automatically set by Braintrust. You should not set these fields yourself, but rather let the SDK create and manage them (even if importing from another system).
When importing spans, the only fields you should need to think about are input, output, expected, scores, metadata, and metrics.
You can use the SDK to populate the remaining fields, which the next section covers with an example.
Here is an example of a span in the underlying format:
Example import/export
The following example walks through how to generate spans in one program and then import them to Braintrust in a script. You can use this pattern to support tracing or running experiments in environments that use programming languages other than TypeScript/Python (e.g. Kotlin, Java, Go, Ruby, Rust, C++), or codebases that cannot integrate the Braintrust SDK directly.
Generating spans
The following example runs a simple LLM app and collects logging information at each stage of the process, without using the Braintrust SDK. This could be implemented in any programming language, and you certainly do not need to collect or process information this way. All that matters is that your program generates a useful format that you can later parse and use to import the spans using the SDK.
Running this script produces output like:
Importing spans
The following program uses the Braintrust SDK in Python to import the spans generated by the previous script. Again, you can modify this program to fit the needs of your environment, e.g. to import spans from a different source or format.
Frequently asked questions
How do I disable logging?
If you are not running an eval or logging, then the tracing code will be a no-op with negligible
performance overhead. In other words, if you do not call initLogger/init_logger/init, in your
code, then the tracing annotations are a no-op.
What happens if Braintrust fails to log a span?
If the Braintrust SDK cannot log for some reason (e.g. a network issue), then your application should not be affected. All logging operations run in a background thread, including api key validation, project/experiment registration, and flushing logs.
When errors occur, the SDK retries a few times before eventually giving up. You'll see loud warning messages when this occurs. And you can tune this behavior via the environment variables defined in Tuning parameters.
How do I trace from languages other than TypeScript/Python?
You can use the Braintrust API to import spans from other languages. See the import/export section for details. We are also exploring support for other languages. Feel free to reach out if you have a specific request.
What are the limitations of the trace data structure? Can I trace a graph?
A trace is a directed acyclic graph (DAG) of spans. Each span can have multiple parents, but most executions are a tree of spans. Currently, the UI only supports displaying a single root span, due to the popularity of this pattern.
Troubleshooting
Tuning Parameters
The SDK includes several tuning knobs that may prove useful for debugging.
BRAINTRUST_SYNC_FLUSH: By default, the SDKs will log to the backend API in the background, asynchronously. Logging is automatically batched and retried upon encountering network errors. If you wish to have fine-grained control over when logs are flushed to the backend, you may setBRAINTRUST_SYNC_FLUSH=1. When true, flushing will only occur when you runExperiment.flush(or any of the other object flush methods). If the flush fails, the SDK will raise an exception which you can handle.BRAINTRUST_MAX_REQUEST_SIZE: The SDK logger batches requests to save on network roundtrips. The batch size is tuned for the AWS lambda gateway, but you may adjust this if your backend has a different max payload requirement.BRAINTRUST_DEFAULT_BATCH_SIZE: The maximum number of individual log messages that are sent to the network in one payload.BRAINTRUST_NUM_RETRIES: The number of times the logger will attempt to retry network requests before failing.BRAINTRUST_QUEUE_SIZE(Python only): The maximum number of elements in the logging queue. This value limits the memory usage of the logger. Logging additional elements beyond this size will block the calling thread. You may set the queue size to unlimited (and thus non-blocking) by passingBRAINTRUST_QUEUE_SIZE=0.BRAINTRUST_QUEUE_DROP_WHEN_FULL(Python only): Useful in conjunction withBRAINTRUST_QUEUE_SIZE. Change the behavior of the queue from blocking when it reaches its max size to dropping excess elements. This can be useful for guaranteeing non-blocking execution, at the cost of possibly dropping data.BRAINTRUST_QUEUE_DROP_EXCEEDING_MAXSIZE(Javascript only): Essentially a combination ofBRAINTRUST_QUEUE_SIZEandBRAINTRUST_QUEUE_DROP_WHEN_FULL, which changes the behavior of the queue from storing an unlimited number of elements to capping out at the specified value. Additional elements are discarded.BRAINTRUST_FAILED_PUBLISH_PAYLOADS_DIR: Sometimes errors occur when writing records to the backend. To aid in debugging errors, you may set this environment variable to a directory of choice, and Braintrust will save any payloads it failed to publish to this directory.BRAINTRUST_ALL_PUBLISH_PAYLOADS_DIR: Analogous toBRAINTRUST_FAILED_PUBLISH_PAYLOADS_DIR, except that Braintrust will save all payloads to this directory.