> ## Documentation Index
> Fetch the complete documentation index at: https://braintrust.dev/docs/llms.txt
> Use this file to discover all available pages before exploring further.
# Tool calls in LLaMa 3.1
[Contributed](https://github.com/braintrustdata/braintrust-cookbook/blob/main/examples/LLaMa-3_1-Tools/LLaMa-3_1-Tools.ipynb) by [Ankur Goyal](https://twitter.com/ankrgyl) on 2024-07-26
LLaMa 3.1 is distributed as an instruction-tuned model with 8B, 70B, and 405B parameter variants. As part of the release, Meta mentioned that
> These are multilingual and have a significantly longer context length of 128K, state-of-the-art tool use, and overall stronger reasoning capabilities.
Let's dig into how we can use these models with tools, and run an eval to see how they compare to gpt-4o on a benchmark.
## Setup
You can access LLaMa 3.1 models through inference services like [Together](https://www.together.ai/), which has generous rate limits and OpenAI protocol compatibility. We'll use Together, through the
[Braintrust proxy](/deploy/ai-proxy) to access LLaMa 3.1 and OpenAI models.
To get started, make sure you have a Braintrust account and an API key for [Together](https://www.together.ai) and [OpenAI](https://platform.openai.com/). Make sure to plug them into your Braintrust account's
[AI secrets](https://www.braintrust.dev/app/settings?subroute=secrets) configuration and acquire a [BRAINTRUST\_API\_KEY](https://www.braintrust.dev/app/settings?subroute=api-keys). Feel free to put your BRAINTRUST\_API\_KEY in a `.env.local` file next to this notebook, or just hardcode it into the code below.
```typescript theme={"theme":{"light":"github-light","dark":"github-dark-dimmed"}}
import dotenv from "dotenv";
import * as fs from "fs";
if (fs.existsSync(".env.local")) {
dotenv.config({ path: ".env.local", override: true });
}
```
```typescript theme={"theme":{"light":"github-light","dark":"github-dark-dimmed"}}
import { OpenAI } from "openai";
import { wrapOpenAI } from "braintrust";
const client = wrapOpenAI(
new OpenAI({
apiKey: process.env.BRAINTRUST_API_KEY,
baseURL: "https://api.braintrust.dev/v1/proxy",
defaultHeaders: { "x-bt-use-cache": "never" },
})
);
const LLAMA31_8B = "meta-llama/Meta-Llama-3.1-8B-Instruct-Turbo";
const LLAMA31_70B = "meta-llama/Meta-Llama-3.1-70B-Instruct-Turbo";
const LLAMA31_405B = "meta-llama/Meta-Llama-3.1-405B-Instruct-Turbo";
const response = await client.chat.completions.create({
model: LLAMA31_8B,
messages: [
{
role: "user",
content: "What is the weather in Tokyo?",
},
],
max_tokens: 1024,
temperature: 0,
});
console.log(response.choices[0].message.content);
```
```
However, I'm a large language model, I don't have real-time access to current weather conditions. But I can suggest some ways for you to find out the current weather in Tokyo:
1. **Check online weather websites**: You can visit websites like AccuWeather, Weather.com, or the Japan Meteorological Agency (JMA) website to get the current weather conditions in Tokyo.
2. **Use a weather app**: You can download a weather app on your smartphone, such as Dark Sky or Weather Underground, to get the current weather conditions in Tokyo.
3. **Check social media**: You can also check social media platforms like Twitter or Facebook to see if there are any updates on the weather in Tokyo.
That being said, I can provide you with some general information about the climate in Tokyo. Tokyo has a humid subtropical climate, with four distinct seasons:
* **Spring (March to May)**: Mild temperatures, with average highs around 18°C (64°F) and lows around 10°C (50°F).
* **Summer (June to August)**: Hot and humid, with average highs around 28°C (82°F) and lows around 22°C (72°F).
* **Autumn (September to November)**: Comfortable temperatures, with average highs around 20°C (68°F) and lows around 12°C (54°F).
* **Winter (December to February)**: Cool temperatures, with average highs around 25°C (77°F).
* **Autumn (September to November)**: Comfort Index: 7/10
* **Autumn (September to November)**: Comfortable temperatures, with average highs around 20°C (68°F) and lows around 12°C (54°F).
* **Winter (December to February)**: Cool temperatures, with average highs around 10°C (50°F) and lows around 2°C (36°F).
Please note that these are general temperature ranges, and the actual weather conditions can vary from year to year.
If you provide me with the PDFs are often related to education, government, or business.
```
As expected, the model can't answer the question without access to some tools. Traditionally, LLaMa models haven't supported tool calling. Some inference providers have attempted to solve this with controlled generation or similar methods, although to limited success. However, the [documentation](https://www.llama.com/docs/model-cards-and-prompt-formats/llama3_1/#json-based-tool-calling) alludes to a new approach to tool calls:
```text theme={"theme":{"light":"github-light","dark":"github-dark-dimmed"}}
Think very carefully before calling functions.
If you choose to call a function ONLY reply in the following format with no prefix or suffix:
{"example_name": "example_value"}
```
Let's see if we can make this work with the commonly used weather tool definition.
```typescript theme={"theme":{"light":"github-light","dark":"github-dark-dimmed"}}
const weatherTool = {
name: "get_current_weather",
description: "Get the current weather in a given location",
parameters: {
type: "object",
properties: {
location: {
type: "string",
description: "The city and state, e.g. San Francisco, CA",
},
},
required: ["location"],
},
};
const toolPrompt = `You have access to the following functions:
Use the function '${weatherTool.name}' to '${weatherTool.description}':
${JSON.stringify(weatherTool)}
If you choose to call a function ONLY reply in the following format with no prefix or suffix:
{"example_name": "example_value"}
Reminder:
- If looking for real time information use relevant functions before falling back to brave_search
- Function calls MUST follow the specified format, start with
- Required parameters MUST be specified
- Only call one function at a time
- Put the entire function call reply on one line
`;
const response = await client.chat.completions.create({
model: LLAMA31_8B,
messages: [
{
role: "user",
content: "What is the weather in Tokyo?",
},
{
role: "user",
content: toolPrompt,
},
],
max_tokens: 1024,
temperature: 0,
});
console.log(response.choices[0].message.content);
```
```
{"location": "Tokyo, JP"}
```
Wow cool! Looks like we can get the model to call the tool. Let's quickly write a parser that can extract the function call from the response.
```typescript theme={"theme":{"light":"github-light","dark":"github-dark-dimmed"}}
function parseToolResponse(response: string) {
const functionRegex = /(.*?)<\/function>/;
const match = response.match(functionRegex);
if (match) {
const [, functionName, argsString] = match;
try {
const args = JSON.parse(argsString);
return {
functionName,
args,
};
} catch (error) {
console.error("Error parsing function arguments:", error);
return null;
}
}
return null;
}
const parsedResponse = parseToolResponse(response.choices[0].message.content);
console.log(parsedResponse);
```
```
{
functionName: 'get_current_weather',
args: { location: 'Tokyo, JP' }
}
```
## A real use case: LLM-as-a-Judge evaluators that make tool calls
At Braintrust, we maintain a suite of evaluator functions in the [Autoevals](https://github.com/braintrustdata/autoevals) library. Many of these evaluators, like `Factuality`, are "LLM-as-a-Judge"
evaluators that use a well-crafted prompt to an LLM to reason about the quality of a response. We are big fans of tool calling, and leverage it extensively in `autoevals` to make it easy and reliable
to parse the scores and reasoning they produce.
As we change autoevals, we run evals to make sure we improve performance and avoid regressing key scenarios. We'll run some of our autoeval evals as a way of assessing how well LLaMa 3.1 stacks up to gpt-4o.
Here is a quick example of the `Factuality` scorer, a popular LLM-as-a-Judge evaluator that uses the following prompt:
```ansi theme={"theme":{"light":"github-light","dark":"github-dark-dimmed"}}
You are comparing a submitted answer to an expert answer on a given question. Here is the data:
[BEGIN DATA]
************
[Question]: {{{input}}}
************
[Expert]: {{{expected}}}
************
[Submission]: {{{output}}}
************
[END DATA]
Compare the factual content of the submitted answer with the expert answer. Ignore any differences in style, grammar, or punctuation.
The submitted answer may either be a subset or superset of the expert answer, or it may conflict with it. Determine which case applies. Answer the question by selecting one of the following options:
(A) The submitted answer is a subset of the expert answer and is fully consistent with it.
(B) The submitted answer is a superset of the expert answer and is fully consistent with it.
(C) The submitted answer contains all the same details as the expert answer.
(D) There is a disagreement between the submitted answer and the expert answer.
(E) The answers differ, but these differences don't matter from the perspective of factuality.
```
```typescript theme={"theme":{"light":"github-light","dark":"github-dark-dimmed"}}
import { Factuality } from "autoevals";
console.log(
await Factuality({
input: "What is the weather in Tokyo?",
output: "The weather in Tokyo is scorching.",
expected: "The weather in Tokyo is extremely hot.",
})
);
```
```
{
name: 'Factuality',
score: 1,
metadata: {
rationale: '1. The expert answer states that the weather in Tokyo is "extremely hot."\n' +
'2. The submitted answer states that the weather in Tokyo is "scorching."\n' +
'3. Both "extremely hot" and "scorching" convey the same factual content, indicating very high temperatures.\n' +
'4. There is no additional information in either answer that would make one a subset or superset of the other.\n' +
'5. Therefore, the submitted answer contains all the same details as the expert answer.',
choice: 'C'
}
}
```
Now let's reproduce this with LLaMa 3.1.
```typescript theme={"theme":{"light":"github-light","dark":"github-dark-dimmed"}}
import { templates } from "autoevals";
import * as yaml from "js-yaml";
import mustache from "mustache";
const template = yaml.load(templates["factuality"]);
const selectTool = {
name: "select_choice",
description: "Call this function to select a choice.",
parameters: {
properties: {
reasons: {
description:
"Write out in a step by step manner your reasoning to be sure that your conclusion is correct. Avoid simply stating the correct answer at the outset.",
title: "Reasoning",
type: "string",
},
choice: {
description: "The choice",
title: "Choice",
type: "string",
enum: Object.keys(template.choice_scores),
},
},
required: ["reasons", "choice"],
title: "CoTResponse",
type: "object",
},
};
async function LLaMaFactuality({
model,
input,
output,
expected,
}: {
model: string;
input: string;
output: string;
expected: string;
}) {
const toolPrompt = `You have access to the following functions:
Use the function '${selectTool.name}' to '${selectTool.description}':
${JSON.stringify(selectTool)}
If you choose to call a function ONLY reply in the following format with no prefix or suffix:
{"example_name": "example_value"}
Reminder:
- If looking for real time information use relevant functions before falling back to brave_search
- Function calls MUST follow the specified format, start with
- Required parameters MUST be specified
- Only call one function at a time
- Put the entire function call reply on one line
`;
const response = await client.chat.completions.create({
model,
messages: [
{
role: "user",
content: mustache.render(template.prompt, {
input,
output,
expected,
}),
},
{
role: "user",
content: toolPrompt,
},
],
temperature: 0,
});
try {
const parsed = parseToolResponse(response.choices[0].message.content);
return {
name: "Factuality",
score: template.choice_scores[parsed?.args.choice],
metadata: {
rationale: parsed?.args.reasons,
choice: parsed?.args.choice,
},
};
} catch (e) {
return {
name: "Factuality",
score: null,
metadata: {
error: `${e}`,
},
};
}
}
console.log(
await LLaMaFactuality({
model: LLAMA31_8B,
input: "What is the weather in Tokyo?",
output: "The weather in Tokyo is scorching.",
expected: "The weather in Tokyo is extremely hot.",
})
);
```
```
{
name: 'Factuality',
score: 0.6,
metadata: {
rationale: "The submitted answer 'The weather in Tokyo is scorching' is not a subset of the expert answer 'The weather in Tokyo is extremely hot' because 'scorching' is not a synonym of 'extremely hot'. However, 'scorching' is a synonym of 'extremely hot' in the context of describing hot weather. Therefore, the submitted answer is a superset of the expert answer and is fully consistent with it.",
choice: 'B'
}
}
```
Ok interesting! It parses but the response is a little different from the GPT-4o response. Let's put this to the test at scale with some evals.
## Running evals
We use a subset of the [CoQA](https://stanfordnlp.github.io/coqa/) dataset to test the Factuality scorer. Let's load the dataset and take a look at an example.
```typescript theme={"theme":{"light":"github-light","dark":"github-dark-dimmed"}}
interface CoqaCase {
input: {
input: string;
output: string;
expected: string;
};
expected: number;
}
const data: CoqaCase[] = JSON.parse(
fs.readFileSync("coqa-factuality.json", "utf-8")
);
console.log("Factuality");
console.log(await Factuality(data[1].input));
console.log("LLaMa-3.1-8B Factuality");
console.log(
await LLaMaFactuality({
model: LLAMA31_8B,
...data[1].input,
})
);
```
```
Factuality
{
name: 'Factuality',
score: 0,
metadata: {
rationale: '1. The question asks about the color of Cotton.\n' +
"2. The expert answer is 'white,' which directly addresses the color of Cotton.\n" +
"3. The submitted answer is 'in a barn,' which does not address the color of Cotton at all.\n" +
'4. Since the submitted answer does not provide any information about the color of Cotton, it conflicts with the expert answer.\n' +
'\n' +
'Therefore, there is a disagreement between the submitted answer and the expert answer.',
choice: 'D'
}
}
LLaMa-3.1-8B Factuality
{
name: 'Factuality',
score: undefined,
metadata: { rationale: undefined, choice: undefined }
}
```
Not bad!
### GPT-4o
Let's run a full eval with gpt-4o, LLaMa-3.1-8B, LLaMa-3.1-70B, and LLaMa-3.1-405B to see how they stack up. Since the evaluator generates a number
between 0 and 1, we'll use the `NumericDiff` scorer to assess accuracy, and a custom `NonNull` scorer to measure how many invalid tool calls are generated.
```typescript theme={"theme":{"light":"github-light","dark":"github-dark-dimmed"}}
import { Eval } from "braintrust";
import { NumericDiff } from "autoevals";
function NonNull({ output }: { output: number | null }) {
return output !== null && output !== undefined ? 1 : 0;
}
const evalResult = await Eval("LLaMa-3.1-Tools", {
data: data,
task: async (input) =>
(
await Factuality({
...input,
openAiDefaultHeaders: { "x-bt-use-cache": "never" },
})
).score,
scores: [NumericDiff, NonNull],
experimentName: "gpt-4o",
metadata: {
model: "gpt-4o",
},
});
```
```
████████████████████████░░░░░░░░░░░░░░░░ | LLaMa-3.1-Tools [experimentName=gpt-4o] | 60% | 60/100 datapoints
```
```
=========================SUMMARY=========================
gpt-4o-8a54393b compared to gpt-4o-c699540b:
100.00% (0.00%) 'NonNull' score (0 improvements, 0 regressions)
86.67% (+3.33%) 'NumericDiff' score (2 improvements, 0 regressions)
4.54s 'duration' (9 improvements, 51 regressions)
0.00$ 'estimated_cost' (20 improvements, 14 regressions)
See results for gpt-4o-8a54393b at https://www.braintrust.dev/app/braintrustdata.com/p/LLaMa-3.1-Tools/experiments/gpt-4o-8a54393b
```
```
```
It looks like GPT-4o does pretty well. Tool calling has been a highlight of OpenAI's feature set for a while, so it's not surprising that it's able to successfully parse 100% of the tool calls.
 ### LLama-3.1-8B, 70B, and 405B
Now let's evaluate each of the LLaMa-3.1 models.
```typescript theme={"theme":{"light":"github-light","dark":"github-dark-dimmed"}}
for (const model of [LLAMA31_8B, LLAMA31_70B, LLAMA31_405B]) {
await Eval("LLaMa-3.1-Tools", {
data: data,
task: async (input) => (await LLaMaFactuality({ model, ...input }))?.score,
scores: [NumericDiff, NonNull],
experimentName: model,
metadata: {
model,
},
});
}
```
```
████████████████████████░░░░░░░░░░░░░░░░ | LLaMa-3.1-Tools [experimentName=meta-... | 60% | 60/100 datapoints
```
```
=========================SUMMARY=========================
meta-llama/Meta-Llama-3.1-8B-Instruct-Turbo compared to gpt-4o:
80.00% (-20.00%) 'NonNull' score (0 improvements, 12 regressions)
68.90% (-19.43%) 'NumericDiff' score (1 improvements, 20 regressions)
3.99s 'duration' (21 improvements, 39 regressions)
0.00$ 'estimated_cost' (60 improvements, 0 regressions)
See results for meta-llama/Meta-Llama-3.1-8B-Instruct-Turbo at https://www.braintrust.dev/app/braintrustdata.com/p/LLaMa-3.1-Tools/experiments/meta-llama%2FMeta-Llama-3.1-8B-Instruct-Turbo
```
```
████████████████████████░░░░░░░░░░░░░░░░ | LLaMa-3.1-Tools [experimentName=meta-... | 60% | 60/100 datapoints
```
```
=========================SUMMARY=========================
meta-llama/Meta-Llama-3.1-70B-Instruct-Turbo compared to meta-llama/Meta-Llama-3.1-8B-Instruct-Turbo:
100.00% (+20.00%) 'NonNull' score (12 improvements, 0 regressions)
90.00% (+21.10%) 'NumericDiff' score (23 improvements, 2 regressions)
5.52s 'duration' (15 improvements, 45 regressions)
0.00$ 'estimated_cost' (0 improvements, 60 regressions)
See results for meta-llama/Meta-Llama-3.1-70B-Instruct-Turbo at https://www.braintrust.dev/app/braintrustdata.com/p/LLaMa-3.1-Tools/experiments/meta-llama%2FMeta-Llama-3.1-70B-Instruct-Turbo
```
```
Error parsing function arguments: SyntaxError: Expected double-quoted property name in JSON at position 36 (line 1 column 37)
at JSON.parse ()
at Proxy.parseToolResponse (evalmachine.:9:31)
at Proxy.LLaMaFactuality (evalmachine.:97:32)
at process.processTicksAndRejections (node:internal/process/task_queues:95:5)
at async Object.task (evalmachine.:5:33)
at async rootSpan.traced.name (/Users/ankur/projects/braintrust/cookbook/content/node_modules/.pnpm/braintrust@0.0.145_openai@4.52.7_react@18.3.1_svelte@4.2.18_vue@3.4.32_zod@3.23.8/node_modules/braintrust/dist/index.js:4488:26)
at async callback (/Users/ankur/projects/braintrust/cookbook/content/node_modules/.pnpm/braintrust@0.0.145_openai@4.52.7_react@18.3.1_svelte@4.2.18_vue@3.4.32_zod@3.23.8/node_modules/braintrust/dist/index.js:4484:11)
at async /Users/ankur/projects/braintrust/cookbook/content/node_modules/.pnpm/braintrust@0.0.145_openai@4.52.7_react@18.3.1_svelte@4.2.18_vue@3.4.32_zod@3.23.8/node_modules/braintrust/dist/index.js:4619:16
Error parsing function arguments: SyntaxError: Expected double-quoted property name in JSON at position 36 (line 1 column 37)
at JSON.parse ()
at Proxy.parseToolResponse (evalmachine.:9:31)
at Proxy.LLaMaFactuality (evalmachine.:97:32)
at process.processTicksAndRejections (node:internal/process/task_queues:95:5)
at async Object.task (evalmachine.:5:33)
at async rootSpan.traced.name (/Users/ankur/projects/braintrust/cookbook/content/node_modules/.pnpm/braintrust@0.0.145_openai@4.52.7_react@18.3.1_svelte@4.2.18_vue@3.4.32_zod@3.23.8/node_modules/braintrust/dist/index.js:4488:26)
at async callback (/Users/ankur/projects/braintrust/cookbook/content/node_modules/.pnpm/braintrust@0.0.145_openai@4.52.7_react@18.3.1_svelte@4.2.18_vue@3.4.32_zod@3.23.8/node_modules/braintrust/dist/index.js:4484:11)
at async /Users/ankur/projects/braintrust/cookbook/content/node_modules/.pnpm/braintrust@0.0.145_openai@4.52.7_react@18.3.1_svelte@4.2.18_vue@3.4.32_zod@3.23.8/node_modules/braintrust/dist/index.js:4619:16
████████████████████████░░░░░░░░░░░░░░░░ | LLaMa-3.1-Tools [experimentName=meta-... | 60% | 60/100 datapoints
```
```
=========================SUMMARY=========================
meta-llama/Meta-Llama-3.1-405B-Instruct-Turbo compared to meta-llama/Meta-Llama-3.1-70B-Instruct-Turbo:
90.57% (+0.57%) 'NumericDiff' score (0 improvements, 2 regressions)
88.33% (-11.67%) 'NonNull' score (0 improvements, 7 regressions)
7.68s 'duration' (23 improvements, 37 regressions)
0.00$ 'estimated_cost' (0 improvements, 60 regressions)
See results for meta-llama/Meta-Llama-3.1-405B-Instruct-Turbo at https://www.braintrust.dev/app/braintrustdata.com/p/LLaMa-3.1-Tools/experiments/meta-llama%2FMeta-Llama-3.1-405B-Instruct-Turbo
```
```
```
### Analyzing the results: LLaMa-3.1-8B
Ok, let's dig into the results. To start, we'll look at how LLaMa-3.1-8B compares to GPT-4o.
### LLama-3.1-8B, 70B, and 405B
Now let's evaluate each of the LLaMa-3.1 models.
```typescript theme={"theme":{"light":"github-light","dark":"github-dark-dimmed"}}
for (const model of [LLAMA31_8B, LLAMA31_70B, LLAMA31_405B]) {
await Eval("LLaMa-3.1-Tools", {
data: data,
task: async (input) => (await LLaMaFactuality({ model, ...input }))?.score,
scores: [NumericDiff, NonNull],
experimentName: model,
metadata: {
model,
},
});
}
```
```
████████████████████████░░░░░░░░░░░░░░░░ | LLaMa-3.1-Tools [experimentName=meta-... | 60% | 60/100 datapoints
```
```
=========================SUMMARY=========================
meta-llama/Meta-Llama-3.1-8B-Instruct-Turbo compared to gpt-4o:
80.00% (-20.00%) 'NonNull' score (0 improvements, 12 regressions)
68.90% (-19.43%) 'NumericDiff' score (1 improvements, 20 regressions)
3.99s 'duration' (21 improvements, 39 regressions)
0.00$ 'estimated_cost' (60 improvements, 0 regressions)
See results for meta-llama/Meta-Llama-3.1-8B-Instruct-Turbo at https://www.braintrust.dev/app/braintrustdata.com/p/LLaMa-3.1-Tools/experiments/meta-llama%2FMeta-Llama-3.1-8B-Instruct-Turbo
```
```
████████████████████████░░░░░░░░░░░░░░░░ | LLaMa-3.1-Tools [experimentName=meta-... | 60% | 60/100 datapoints
```
```
=========================SUMMARY=========================
meta-llama/Meta-Llama-3.1-70B-Instruct-Turbo compared to meta-llama/Meta-Llama-3.1-8B-Instruct-Turbo:
100.00% (+20.00%) 'NonNull' score (12 improvements, 0 regressions)
90.00% (+21.10%) 'NumericDiff' score (23 improvements, 2 regressions)
5.52s 'duration' (15 improvements, 45 regressions)
0.00$ 'estimated_cost' (0 improvements, 60 regressions)
See results for meta-llama/Meta-Llama-3.1-70B-Instruct-Turbo at https://www.braintrust.dev/app/braintrustdata.com/p/LLaMa-3.1-Tools/experiments/meta-llama%2FMeta-Llama-3.1-70B-Instruct-Turbo
```
```
Error parsing function arguments: SyntaxError: Expected double-quoted property name in JSON at position 36 (line 1 column 37)
at JSON.parse ()
at Proxy.parseToolResponse (evalmachine.:9:31)
at Proxy.LLaMaFactuality (evalmachine.:97:32)
at process.processTicksAndRejections (node:internal/process/task_queues:95:5)
at async Object.task (evalmachine.:5:33)
at async rootSpan.traced.name (/Users/ankur/projects/braintrust/cookbook/content/node_modules/.pnpm/braintrust@0.0.145_openai@4.52.7_react@18.3.1_svelte@4.2.18_vue@3.4.32_zod@3.23.8/node_modules/braintrust/dist/index.js:4488:26)
at async callback (/Users/ankur/projects/braintrust/cookbook/content/node_modules/.pnpm/braintrust@0.0.145_openai@4.52.7_react@18.3.1_svelte@4.2.18_vue@3.4.32_zod@3.23.8/node_modules/braintrust/dist/index.js:4484:11)
at async /Users/ankur/projects/braintrust/cookbook/content/node_modules/.pnpm/braintrust@0.0.145_openai@4.52.7_react@18.3.1_svelte@4.2.18_vue@3.4.32_zod@3.23.8/node_modules/braintrust/dist/index.js:4619:16
Error parsing function arguments: SyntaxError: Expected double-quoted property name in JSON at position 36 (line 1 column 37)
at JSON.parse ()
at Proxy.parseToolResponse (evalmachine.:9:31)
at Proxy.LLaMaFactuality (evalmachine.:97:32)
at process.processTicksAndRejections (node:internal/process/task_queues:95:5)
at async Object.task (evalmachine.:5:33)
at async rootSpan.traced.name (/Users/ankur/projects/braintrust/cookbook/content/node_modules/.pnpm/braintrust@0.0.145_openai@4.52.7_react@18.3.1_svelte@4.2.18_vue@3.4.32_zod@3.23.8/node_modules/braintrust/dist/index.js:4488:26)
at async callback (/Users/ankur/projects/braintrust/cookbook/content/node_modules/.pnpm/braintrust@0.0.145_openai@4.52.7_react@18.3.1_svelte@4.2.18_vue@3.4.32_zod@3.23.8/node_modules/braintrust/dist/index.js:4484:11)
at async /Users/ankur/projects/braintrust/cookbook/content/node_modules/.pnpm/braintrust@0.0.145_openai@4.52.7_react@18.3.1_svelte@4.2.18_vue@3.4.32_zod@3.23.8/node_modules/braintrust/dist/index.js:4619:16
████████████████████████░░░░░░░░░░░░░░░░ | LLaMa-3.1-Tools [experimentName=meta-... | 60% | 60/100 datapoints
```
```
=========================SUMMARY=========================
meta-llama/Meta-Llama-3.1-405B-Instruct-Turbo compared to meta-llama/Meta-Llama-3.1-70B-Instruct-Turbo:
90.57% (+0.57%) 'NumericDiff' score (0 improvements, 2 regressions)
88.33% (-11.67%) 'NonNull' score (0 improvements, 7 regressions)
7.68s 'duration' (23 improvements, 37 regressions)
0.00$ 'estimated_cost' (0 improvements, 60 regressions)
See results for meta-llama/Meta-Llama-3.1-405B-Instruct-Turbo at https://www.braintrust.dev/app/braintrustdata.com/p/LLaMa-3.1-Tools/experiments/meta-llama%2FMeta-Llama-3.1-405B-Instruct-Turbo
```
```
```
### Analyzing the results: LLaMa-3.1-8B
Ok, let's dig into the results. To start, we'll look at how LLaMa-3.1-8B compares to GPT-4o.
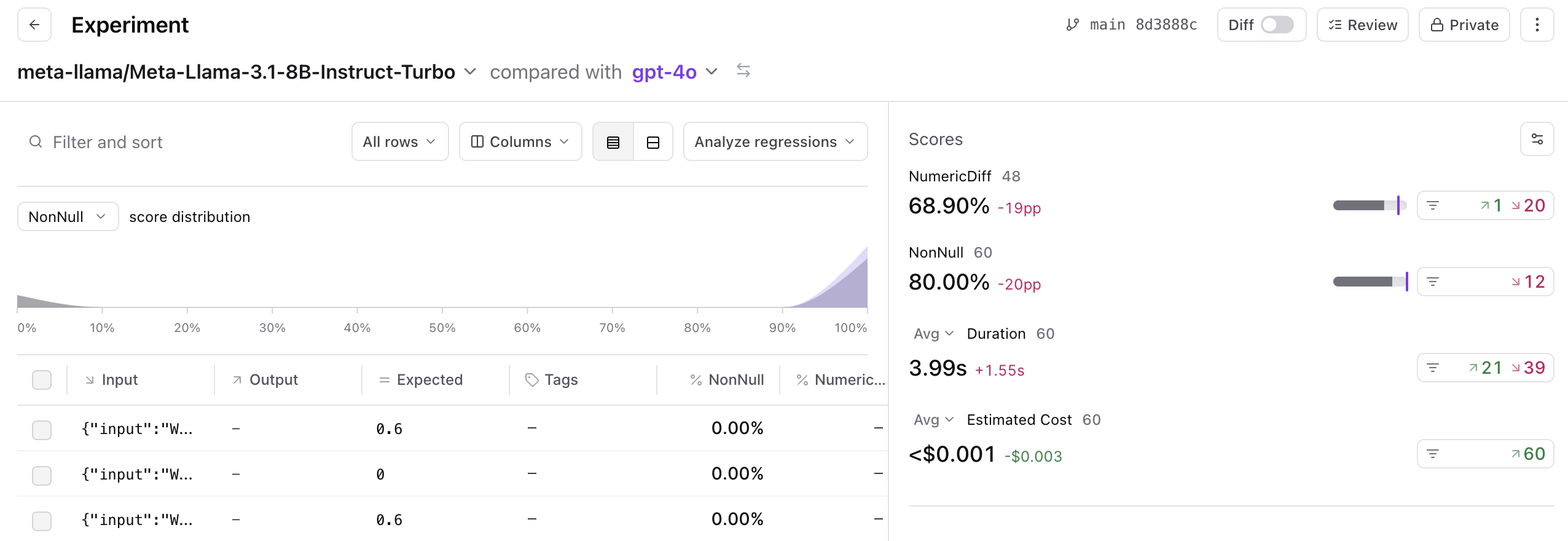 Although it's a fraction of the cost, it's both slower (likely due to rate limits) and worse performing than GPT-4o. 12 of the 60 cases failed to parse. Let's take a look at one of those in depth.
Although it's a fraction of the cost, it's both slower (likely due to rate limits) and worse performing than GPT-4o. 12 of the 60 cases failed to parse. Let's take a look at one of those in depth.
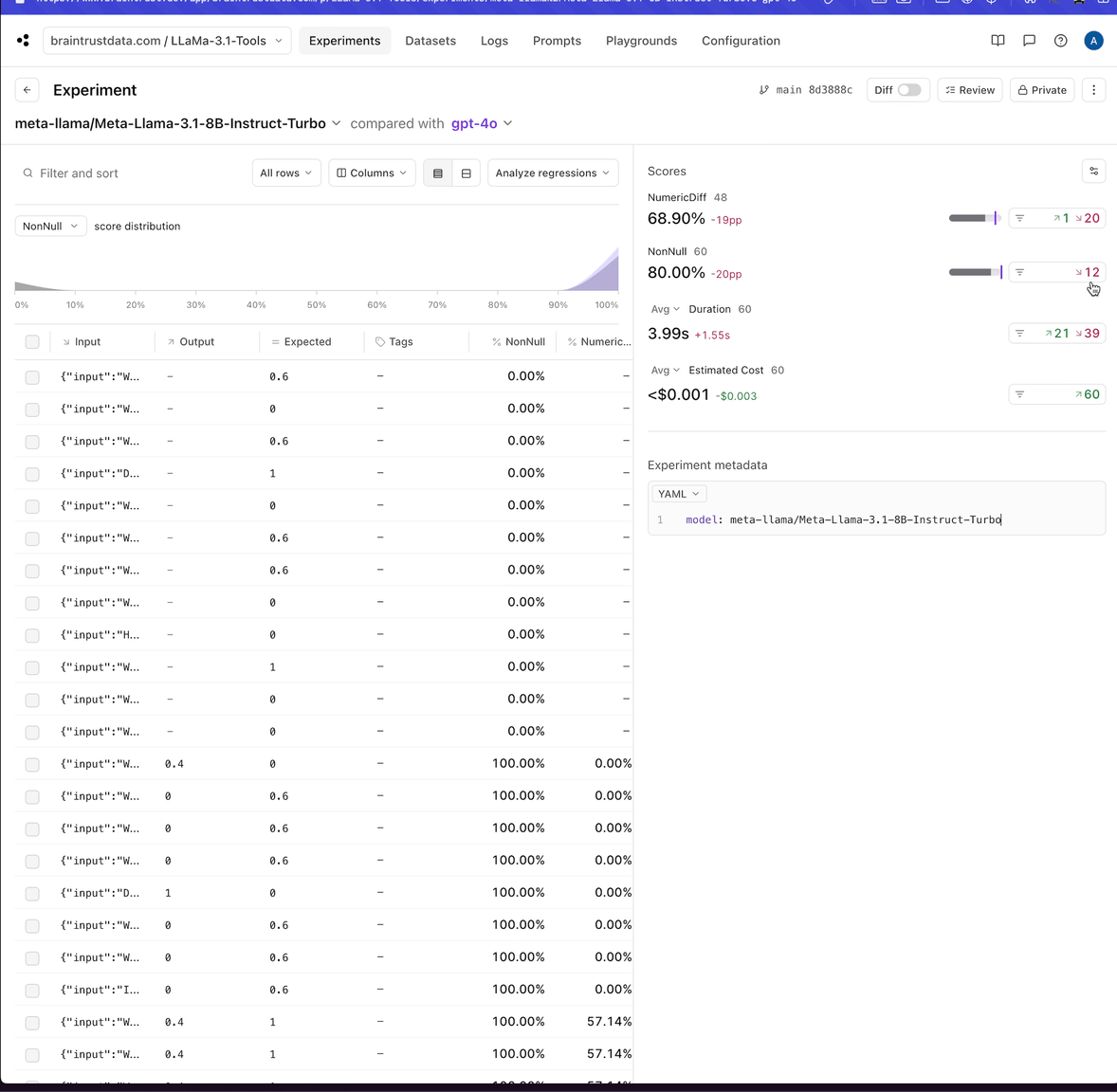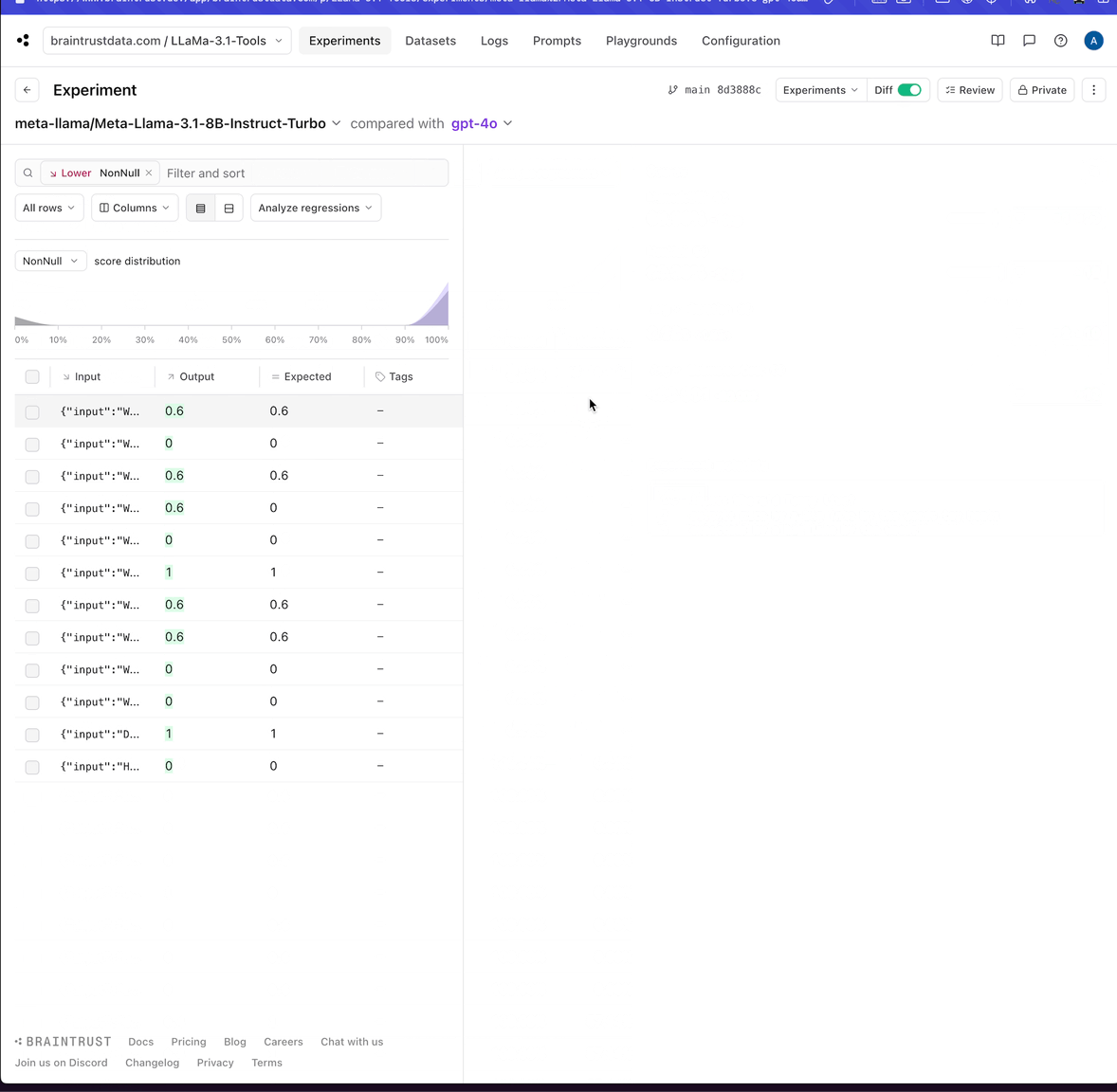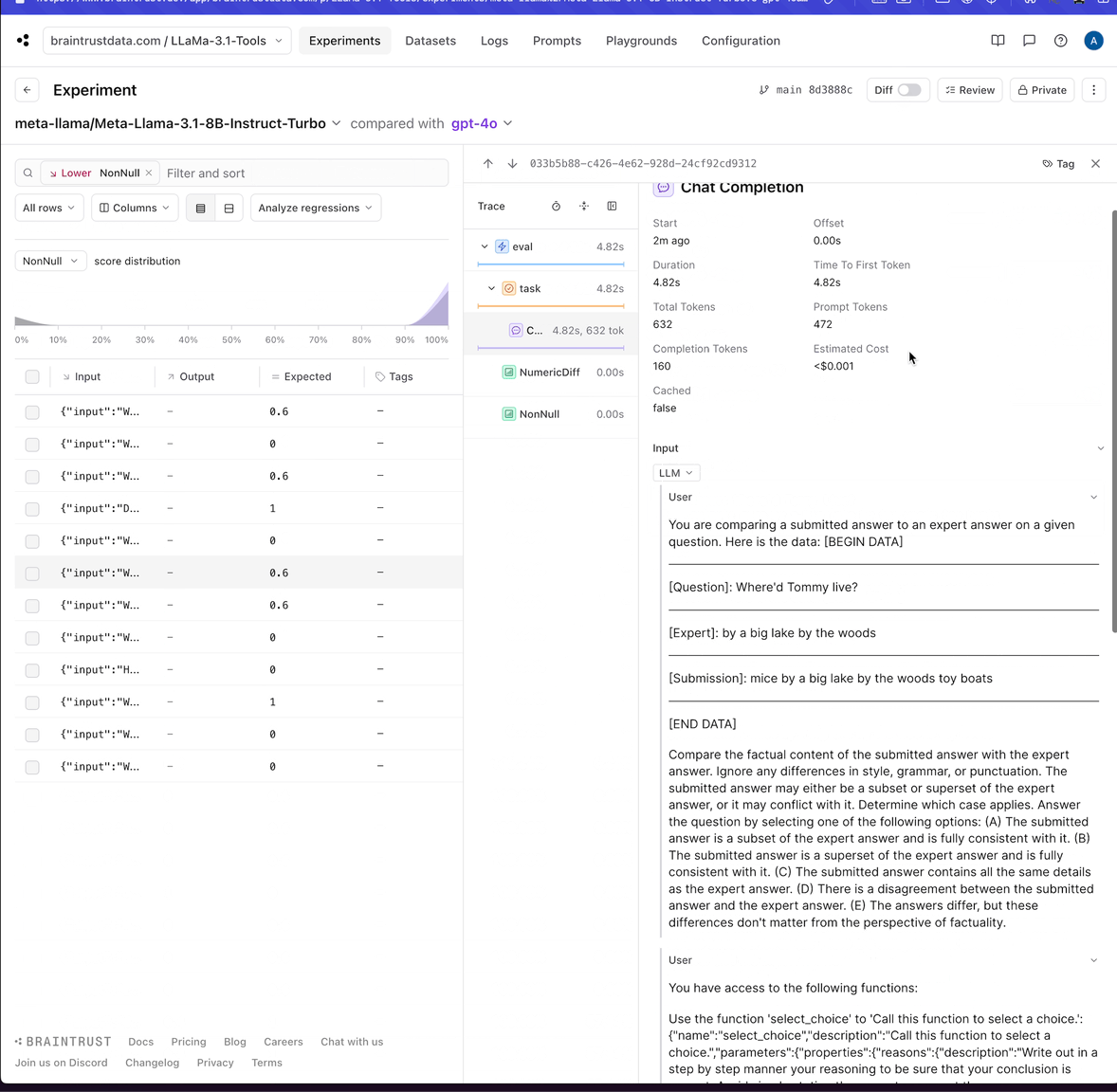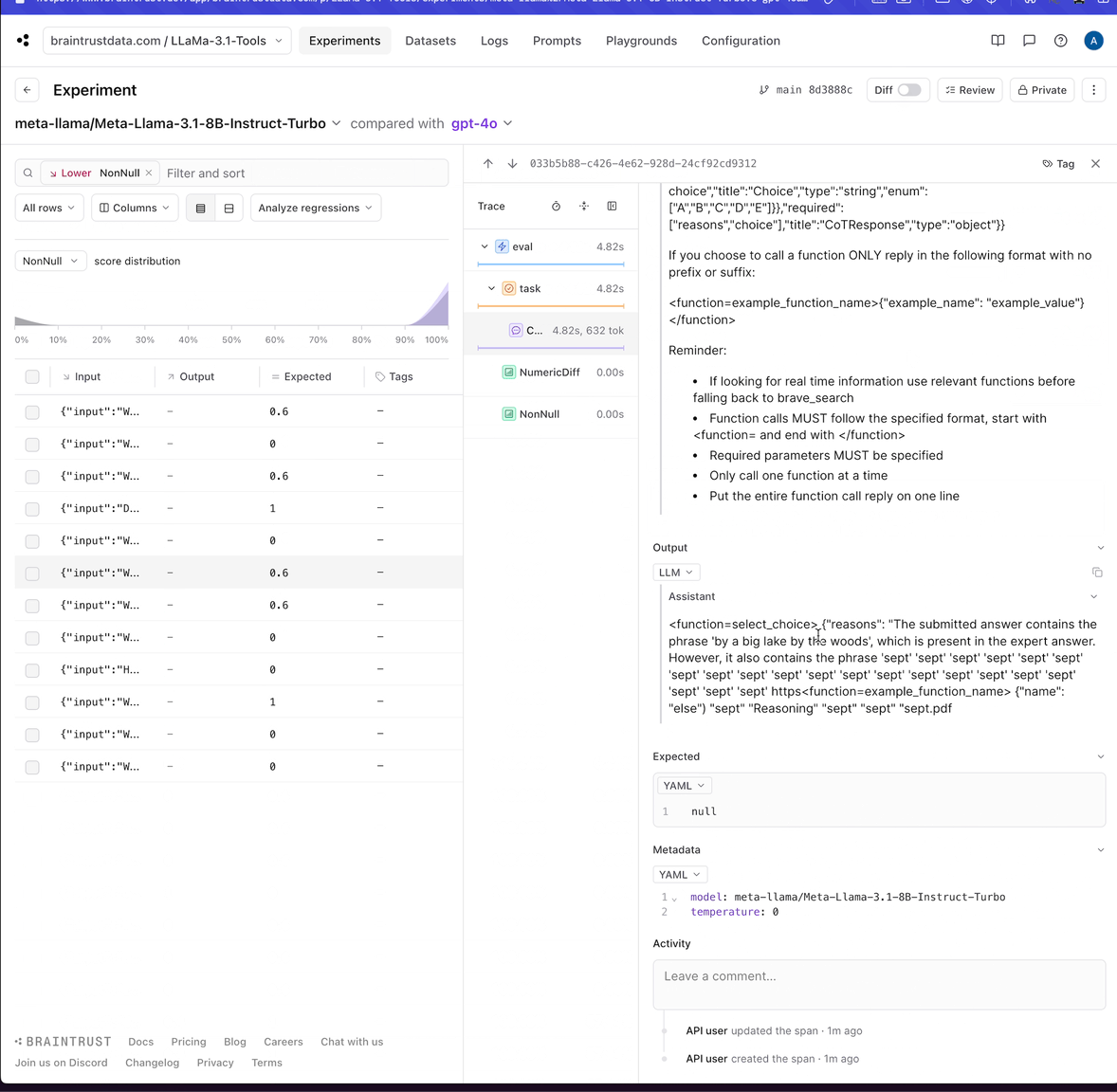 That definitely looks like an invalid tool call. Maybe we can experiment with tweaking the prompt to get better results.
### Analyzing all models
If we look across models, we'll start to see some interesting takeaways.
That definitely looks like an invalid tool call. Maybe we can experiment with tweaking the prompt to get better results.
### Analyzing all models
If we look across models, we'll start to see some interesting takeaways.
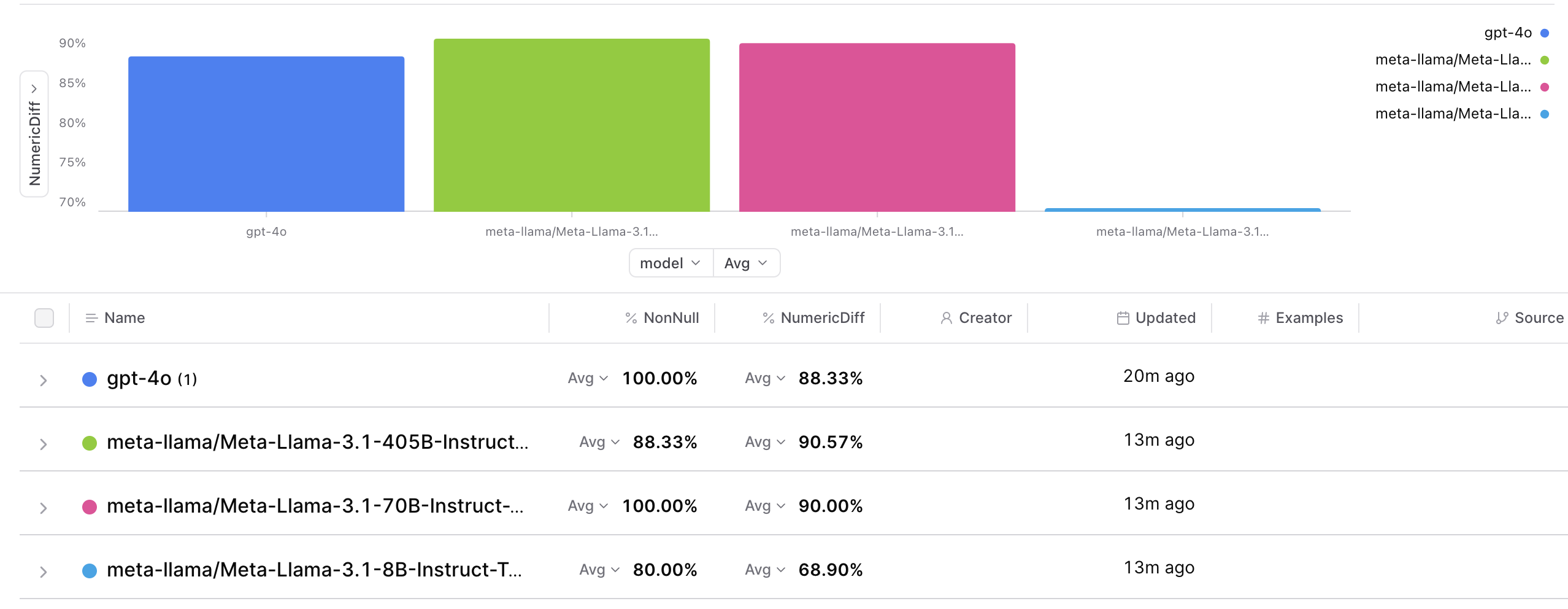 * LLaMa-3.1-70B has no parsing errors, which is better than LLaMa-3.1-405B!
* Both LLaMa-3.1-70B and LLaMa-3.1-405B performed better than GPT-4o, although by a fairly small margin.
* LLaMa-3-70B is less than 25% the cost of GPT-4o, and is actually a bit better.
## Where to go from here
In just a few minutes, we've cracked the code on how to perform tool calls with LLaMa-3.1 models and run a benchmark to compare their performance to GPT-4o. In doing so, we've
found a few specific areas for improvement, e.g. parsing errors for tool calls, and a surprising outcome that LLaMa-3.1-70B is better than both LLaMa-3.1-405B and GPT-4o, yet a
fraction of the cost.
To explore this further, you could:
* Expand the benchmark to measure other kinds of evaluators.
* Try providing few-shot examples or fine-tuning the models to improve their performance.
* Play with other models, like GPT-4o-mini or Claude to see how they compare.
Happy evaluating!
* LLaMa-3.1-70B has no parsing errors, which is better than LLaMa-3.1-405B!
* Both LLaMa-3.1-70B and LLaMa-3.1-405B performed better than GPT-4o, although by a fairly small margin.
* LLaMa-3-70B is less than 25% the cost of GPT-4o, and is actually a bit better.
## Where to go from here
In just a few minutes, we've cracked the code on how to perform tool calls with LLaMa-3.1 models and run a benchmark to compare their performance to GPT-4o. In doing so, we've
found a few specific areas for improvement, e.g. parsing errors for tool calls, and a surprising outcome that LLaMa-3.1-70B is better than both LLaMa-3.1-405B and GPT-4o, yet a
fraction of the cost.
To explore this further, you could:
* Expand the benchmark to measure other kinds of evaluators.
* Try providing few-shot examples or fine-tuning the models to improve their performance.
* Play with other models, like GPT-4o-mini or Claude to see how they compare.
Happy evaluating!